论文:InfoColorizer: Interactive Recommendation of Color Palettes for Infographics
作者:Lin-Ping Yuan, Ziqi Zhou, Jian Zhao, Yiqiu Guo, Fan Du, Huamin Qu
发表:VIS, 2021
在信息图设计时,一般的用户会使用已有的信息图工具得到期望的配色,而这有时会损失配色的灵活性,或者要求用户有专业的设计知识,或者忽略了元素的空间安排。本文提出了一个数据驱动的方法,能够在考虑用户偏好的情况下保证配色的灵活度,通过自动化方法降低对专业知识的要求,并根据元素的空间布局合理修正配色方案。
introduction
信息图是一个非常有效的产达抽象信息的手段。除了图表元素的内容和结构,元素的颜色和其组合——配色,也是十分重要的,这影响到审美、可记忆性等方面。但是,构建一个信息图和为他选择配色都不是一个简单的工作,尤其是当用户缺少专业的设计经验时,这是因为配色需要同时考虑很多因素,包括布局,外观、感知的有效性等。尽管有一些创作工具支持创建信息图,但是这些工具却不能提供合适的颜色设计方案。用户只能自己进行人工配色,否则只能选择工具已经预设好的一些方案。
使用当前工具进行配色由主要三个挑战:
从一些已有的样本中创建配色方案需要相关的专业知识
使用预定义的配色方案限制了用户的自由性
- 由于元素的空间布局问题,将配色方案应用到图标上也是十分复杂的过程
为此我们提出了一个可交互的工具,infoColorizer,允许用户使用数据驱动方法在创建图表的过程中高效的设计出配色方案。我们使用深度学习方法从大量图表数据集中抽取配色设计,然后学习出一个模型来推荐合适的配色方案。这降低了用户创建配色方案的专业门槛。我们将学习过程建模为条件生成过程,使用VAEAC(带任意条件的变分编码器)来根据用户设定的条件动态推荐配色。
主要贡献:
- 一个新的数据驱动的方法,使用深度学习方法在考虑元素的空间排布下推荐配色方案,同时给用户偏好一定的自由度
- 一个可交互工具,infoColorizer,采用数据驱动的推荐方法,更加简单便于管理,同时支持迭代设计和信息图编辑
- 通过一系列case study和user study、online survry、interview study得到了相应的insights和结果
设计和概览
系统的设计目标主要有以下几点:
- 降低建立专业配色方案的所需专业需求
- 提供灵活性,能够嵌入不同的用户偏好
- 考虑元素的空间布局
- 支持简单的用户交互和配色方案的迭代设计
本系统的架构如图所示:
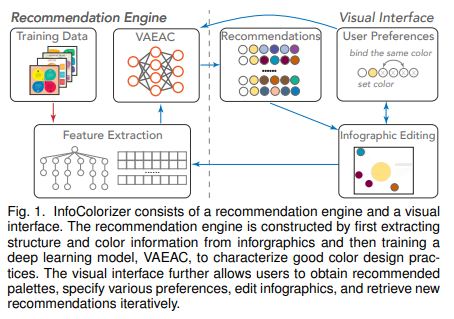
如图,本系统使用一个数据驱动方法来自动从信息图数据集中学习到好的设计,然后使用学习到的知识来推荐配色,同时提供可视化界面来允许用户对推荐结果进行交互。
信息图I,包含Ei(维度为n),表示元素;而I表示为一个无颜色特征集合F(维度为m)和颜色特征C(维度为n)F包含了不同粒度的信息(信息图和元素层级)和元素的空间排布信息,这些结合起来表示为一个树型结构。对于专家设计的信息图,颜色特征C和与特征F的关系反映出好的设计,这是我们希望捕捉到的信息。
我们把推荐过程建模为条件生成模型,VAEAC,该模型能够将任意特征作为条件,具有灵活性。具体来说,给定专家设计的信息图集合,模型可以学习到全特征集合(无颜色特征F和颜色C)上的概率分布,进而捕捉到好的设计。进一步地,学习到的模型可以在给定信息图I和其余特征的情况下用来生成一些丢失特征。例如,用户确定颜色两个元素的颜色Ci和Cj,那么生成模型就从相应的条件分布中采样,这允许了在给定用户偏好下的灵活性。为了以上的推荐更加容易获取和配置,根据需要设计了可视交互系统infoColorizer
信息图的概念模型
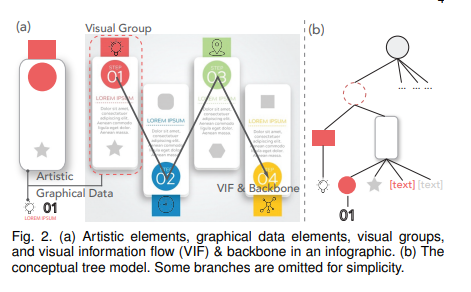
如图,信息图可以看做一些艺术装饰的组合(形状、图像、 clipart 剪贴画)和图形数据元素(icon、文本、indices)。图形数据元素组织成visual group来传达信息。visual group进一步按照序列顺序展示,成为可视信息流(VIF),来进行信息图叙事。连接各个组的语义中心的所形成的路径称为可视信息流的backbone。
但是这个信息图模型在本case中不够充分,因为他只考虑了图形数据元素。这有些过度简化了,因为艺术装饰和他们的颜色影响信息图的美感,因此决定合适的配色是很重要的。进一步,细节的空间关系也会影响配色设计。比如两个相邻的元素可能会使用相同的颜色来暗示相似性;一个完全包含另一个元素的元素可能会选择更高的对比度。
为此,我们在此模型基础上进行扩展,将艺术元素也包含在visual group中,VIF同理。由于树经常用来描述分析图像的拓扑结构,我们这里也采用树结构,从空间角度来对信息图进行刻画。根节点表示整个信息图,第二层表示所有的visual group,第三层艺术元素和图形数据元素。这样父子连接表示了元素的包含关系,兄弟节点表示在布局中的相邻关系。这样概念模型从逻辑和空间两个角度对信息图进行了刻画,可以允许数据驱动模型从中抽取关系。
系统设计
使用多种特征刻画信息图
对于图I,需要一组颜色C和非颜色特征F来描述其外观和空间布局。
我们抽取所有元素的颜色和背景的颜色作为C(使用CIELab颜色空间)。再在不同的层级上提取一些列非颜色特征F。具体地,在信息图层级上,提取VIF的类别、visual group数量、visual group距离。在visual group维度上,提取元素数量、相对组大小,在元素层级上,提取元素种类,相对大小和相对像素区域。
树结构的击退表示方法参照原论文见附录A。
使用推荐降低专业门槛
下一步是训练模型。这里使用VAEAC作为深度学习模型。
VAE包含两步,一个是编码器,一个是解码器,这里x是信息图特征F,C,潜变量z反映了数据中的抽象知识
我们希望根据F反映的特定的信息图结构设计来得到配色,这是一个条件生成过程。此外,用户还可能会有其他的配色偏好,这表示C的一部分也在条件中。VAEVC通过一个二元mask b可以控制x的哪一部分是条件。一般来说,模型使用完整输入x的进行训练,训练的得到的模型能够对任意输入x的未观测部分(或丢失部分)进行补全。本例子中,特征F视为观测部分,颜色C的一部分为观测部分,用户决定mask b。如果C完全不观测,那么模型产生完整的配色方案,如果C观测一部分,那么就产生带有偏好的配色方案。
本文还测试了其他模型
GAIN (Generative Adversarial Imputation Nets,GAN在特征补全的sota)
MICE (Multivariate Imputation by Chained Equations,经典的非深度学习方法)
结果显示VAEAC表现最好,具体结果在附录B部分。
为多种用户偏好提供灵活性
模型在配色推荐上也支持灵活性控制,主要支持两种用户约束:
1.确定特定元素的颜色,可以使准确指定或模糊指定
这里分配准确颜色即直接指定C特征;模糊分配指的是使用单词进行指定。本工作搜集了200个颜色单词来进行匹配,每个单词对应一组颜色,当一个单词分配到元素i时我们随机挑选k个相应颜色然后产生k个输入向量,再输入系统产生k个结果,最后进行随机选择。
2.绑定几个元素使其有相同的颜色
这里绑定元素使用一个在推荐结果上进行后处理的方法,比如绑定三个元素,那么在结果中先根据基于面积产生的概率随机选择一个,然后把三个元素设置成所选元素的颜色以实现颜色绑定的效果。
用可视界面支持用户工作流

系统如图所示,界面包含了三个主要部分。
内容库(A)
保存图形,图像、icon等素材和信息图模型,用户可以从素材中创建或者从模板创建,然后使用系统的配色推荐进行着色,用户也可以自行上传素材,修改信息图或者颜色。
主界面(B)
选择资源后在此编辑。上方工具栏支持一些简单的编辑函数比如排布、分组、复制、删除。
控制面板(C)
核心组件,用户在这里得到想要的配色方案,迭代的进行偏好确认、或者推荐、修正设计,
此外系统提供了设置偏好的组件(C1)
这里举个例子来描述系统使用过程。一个市场经理想要改进信息图,他先选择分析信息图,然后分析得到元素的空间关系得到树结构(C1)。树代表了信息图概念模型,可视化为水平层上的矩形。最底层是背景,第二层是背景上直接放置的元素,以此类推。矩形颜色表示了用户的偏好,带有斜线的空矩形表示无偏好。
最初,他想背景亮一些,字体是统一纯白色。那么在C1,他使用单词light指定背景颜色,light单词会显示在矩形旁边。然后他将四个文字设定为白色,这需要颜色指定和颜色绑定。绑定的元素在下侧会有统一的红点标识,这样的配置结果显示在CP1中。
然后点击get recommendations,C4中或返回一组推荐配色,本例为④,推荐数量可以调整。他选择而其中喜欢的一个,如P1,进行预览和调整。然后配色会被拷贝给颜色偏好,见CP2;随后信息图自动着色,见⑤。
接下来,他不满第一个和最后一个bar的颜色,那么选择删除这两个bar的颜色,如CP3,然后按照这个偏好请求新的推荐,结果如③,和之前的迭代一样,他选择喜欢的配色如P2,然后更新偏好和信息图,得到满意的结果后导出。
评估
本文进行四部分评估。首先进行case研究,探究系统能够在不同场景下产生吸引人的配色。此外我们从新手创建者、信息图读者和图形设计专家的角度定量定性评估系统,分别进行user study、survey study和interview study。这些研究反映了系统不同方面的强弱,细节在补充材料中。
case studies
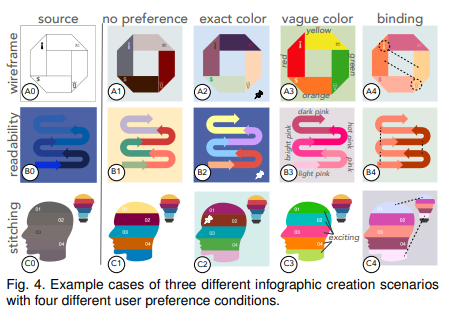
图中提出了一组使用推荐配色信息图图。更多例子在补充材料中。
我们研究了在不同的用户偏好和限制下系统的配色推荐情况。我们考虑三个use case:
a) 线框图上色
b) 提升颜色可读性
c) 缝合两个不同配色的信息图
和四个条件;
无偏好、准确颜色指定、模糊颜色指定、元素绑定
可以看到,即使没有颜色偏好,系统也能够给出令人信服的颜色推荐,例如A1中四种颜色都很平滑一致。C1中,用户希望头的配色跟随灯泡配色,因此固定了灯泡查询头的颜色推荐,系统推荐出了和灯泡相似的配色,说明模型能够利用可观测颜色。此外A2,B2中背景分匹配了颜色,进而推荐出的颜色都有增强或和背景形成对比。进一步,使用单词指定颜色,系统返回了一些符合美学的信息图,比如B3中用户想要一个粉色主题的但不知道具体是什么,因此就使用单词指定。最后,使用绑定元素,用户可以得到一致的配色,比如B4和C4。
user study
我们进行了研究来评估系统对于真实用户在配色设计任务上的效果。
这个研究主要是为了探究工作流的两个方面:
1.系统是否能够帮助用户获得令他们满意的配色
2.系统是否能支持用户的配色构建和设计
用户进行的任务如下所示:
提供四个实验信息图,参加者需要完成两个任务:
任务1评估工具的有效性。参加者需要在四张图中为三张上色直到他们满意为止,无时间限制。
任务2评估系统所支持的创造性。参加者要在15min内对剩余一张图上色,尽可能获得更多的满意结果。
实验结果如图所示。
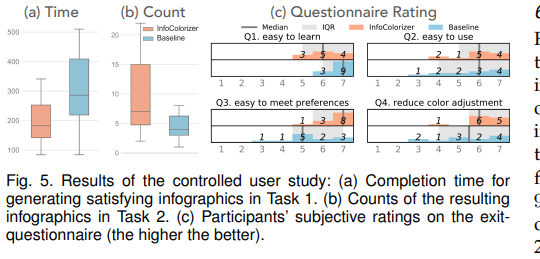
任务一中两种方法完成时间差异的显著性p值<<0.001,任务二中两种方法下创建的信息图个数差异的显著性p值=0.02。这表明任务一中参加者使用本系统生产层信息图更快,任务二中参加者常见了更多的满意的信息图。
分析调查问卷,可以得到如下结果:
问题一,p=0.014,大概因为本系统由于存在推荐可能更加复杂,不过评分都在5以上表明系统复杂程度也是有限的。
问题二,p=0.32,没有显著差异,但是本系统的正向评分更多。原因是本系统有推荐功能,可以有效的帮助信息减小搜索空间。
问题三,p=0.007,有显著差异,表明本系统可能简单的在约束下对信息图进行时上色。
问题四,p=0.091,没有显著差异,但是系统的评分均值更高,评分方差更小,这表明系统在减小用户颜色调整的负担上有稳定性。
利用 Creativity Support Index ,可以量化一个工具能够多好的支持用户的创造性。我们让用户从五个因素对系统打分,包括吸引力,探索,结果是否值得努力,沉浸( Immersion),快乐(Enjoyment)。下表显示了每个因素的评分,基于此我们计算CSI分数
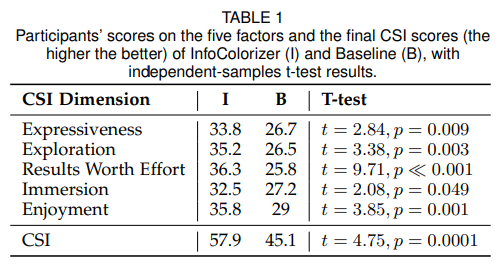
可以看到,系统57.9评分高于baseline的45.1,t检验表明明显著性为0.00001,说明是显著高于。此外在所有因素上本系统都高于baseline。尽管一些推荐低于预期,用户也任务整体的结果是可以接受的,系统的配色修正的工作流也比baseline好。
survey study
从消费者的角度生成的信息图效果如何呢?为了回答这一问题,本文设计了survey研究,比较了本系统和一些其他方法,包括艺术家设计、系统推荐、baseline创建、colorbrewer预定义、随机生成。
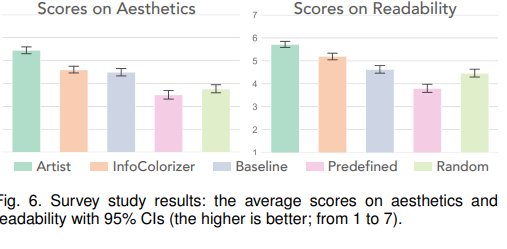
可以看到艺术家设计的评分最好。除此之外,系统推荐的最好。另外,系统推荐和baseline在美学评分上没有显著差异,但在可读性上有差异。这表明系统不止改进了用户的创作效率,也保证推荐配色知道有和用户手动创建和basline相同水平的美学和可读性。
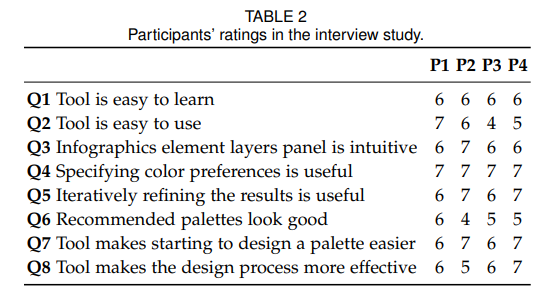
interview study
前面研究都是针对新手,系统在专家的眼里表现如何?结果如下表所示。
讨论
对不同信息图的泛化
当前系统针对的信息图都是可以描述为本文提到的概念模型的信息图。但是也有很多信息图包含数据表,比如折线图散点图。数据集中存在1%的这样的样本,尽管比例很小,但是系统无法为这样的信息图进行推荐,因为数据嵌入没有在输入中很好刻画。可以通过结合其他数据表工具解决本问题。比如先使用其他工具单独对数据表着色,在使用本系统为其他部分着色。进一步我们可以将这一也自动化。
显示和隐式的颜色约束
推荐配色时,我们只考虑用户显示指定的颜色偏好,而不管信息图中的一些可能的隐式约束。比如一个信息图中可能用一组连续的颜色编码数据,但是本系统不能保证结果有这样的关系。解决方法是把这样的颜色关系也嵌入特征向量,训练模型学习这样的关系。
泛化和个性的权衡
本方法是数据驱动的,这表示推荐的风格和质量依赖于训练数据。更多的训练数据会提高泛化性和准确性。但是一个配色是不是符合美学的还是一个主观问题。一个可能方法是模型的训练针对能不同个人,活着基于用户对结果的选择逐渐优化,已达到对每个用户的个性化定制效果。
其他局限
study设计的局限
对比用的方法使用了随机策略
interview的样本数量比较少
✉️ zjuvis@cad.zju.edu.cn